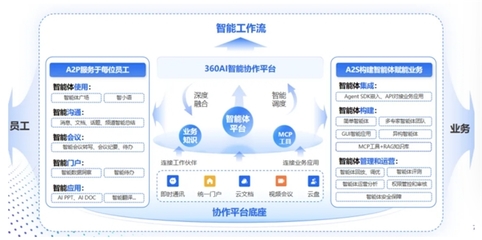
人工智能已成為全球科技競爭的核心領域,其發展高度依賴于兩大基石:高質量的基礎數據服務和穩健的基礎軟件開發。在中國,這兩個領域正經歷著前所未有的深度融合與協同發展,共同構成了AI產業生態的堅實底座。
一、人工智能基礎數據服務行業:智能模型的“燃料”與“標尺”
中國的人工智能基礎數據服務行業,伴隨著AI應用的爆發式增長,已從早期簡單的數據標注,演變為一個專業化、精細化、規模化的關鍵產業。該行業的核心任務是為機器學習算法提供訓練、驗證和測試所需的高質量數據。
- 市場現狀與規模:在政策支持、資本涌入和市場需求(尤其是在自動駕駛、智慧金融、智能安防、內容審核等領域)的三重驅動下,行業規模持續擴大。服務內容已涵蓋多模態數據(文本、語音、圖像、視頻、3D點云等)的采集、清洗、標注、質檢、管理乃至合成,服務模式也從項目制向平臺化、自動化方向發展。
- 發展趨勢:
- 專業化與場景化:需求從通用標注轉向對特定行業(如醫療影像分割、法律文書理解)有深刻理解的深度標注服務。
- 技術賦能:利用AI輔助標注工具提升效率與一致性,人機協同成為主流。數據合成技術為解決稀缺場景、隱私敏感數據提供了新路徑。
- 質量與安全并重:數據質量評估體系日趨嚴格,數據安全與隱私保護(如聯邦學習支持)成為核心競爭力。
- 標準化探索:行業正積極推動數據標注流程、質量標準和安全規范的建立。
行業也面臨挑戰,包括人力成本上升、對復雜場景數據處理能力不足、數據產權與倫理規范尚不清晰等。
二、人工智能基礎軟件開發:智能系統的“引擎”與“框架”
基礎軟件開發為AI應用提供了核心的計算能力、算法模型和開發環境。中國的AI基礎軟件生態正在快速構建,力圖在關鍵環節實現自主可控。
- 核心構成:主要包括深度學習框架(如百度的PaddlePaddle、華為的MindSpore)、AI芯片配套軟件棧、模型開發與部署工具、大數據處理平臺以及新興的MaaS(模型即服務)平臺。
- 發展特點:
- 框架層競爭加劇:國內主流框架在易用性、產業適配和開源生態建設上持續投入,與TensorFlow、PyTorch等國際框架形成差異化競爭,尤其在國產硬件適配和產業落地方面優勢漸顯。
- 全棧優化成為關鍵:從芯片指令集、算子庫、計算圖編譯到推理引擎,軟硬件協同優化是釋放算力潛能、提升應用性能的必由之路。
- 標準化與開源化:通過參與或主導開源項目、推動行業標準,構建開放協作的生態體系,降低開發門檻。
- 聚焦大模型與工程化:為應對超大規模預訓練模型的開發、訓練、微調與高效部署,基礎軟件在分布式訓練、模型壓縮、推理加速等方面的能力至關重要。
挑戰在于核心底層技術(如高端AI芯片、最前沿算法)與國際領先水平仍有差距,生態的豐富度和全球影響力有待進一步提升。
三、協同共生:數據與軟件的“雙螺旋”
人工智能基礎數據服務與基礎軟件開發并非孤立發展,而是形成了緊密耦合、相互促進的“雙螺旋”結構。
- 數據服務驅動軟件創新:日益復雜的數據處理需求(如4D標注、多模態對齊)倒逼基礎軟件提供更強大的數據加載、預處理和增強工具。高質量、場景化的數據集也是訓練和評測AI框架與算法性能的基準。
- 基礎軟件賦能數據產業:強大的深度學習框架和自動化工具使數據標注的智能化水平大幅提升,降低了人力依賴和成本。高效的模型訓練與推理軟件也加速了數據價值閉環的驗證。
- 共同支撐應用落地:兩者共同為上層AI應用提供“數據原料”和“生產工具”,是產業智能化轉型不可或缺的基礎設施。在自動駕駛、科學智能(AI for Science)等前沿領域,對高精度數據與專用軟件棧的協同要求尤為突出。
四、未來展望
中國AI基礎層的發展將呈現以下路徑:
- 深化融合:數據服務平臺將更深地集成模型訓練與評估功能,而基礎軟件將原生提供更完善的數據處理流水線,兩者邊界進一步模糊。
- 追求高質量與自動化:在數據側,自動化、智能化的數據生產線是方向;在軟件側,自動化機器學習(AutoML)、低代碼開發將降低AI使用門檻。
- 強化安全與治理:數據安全、隱私計算、模型可信(可解釋、公平、魯棒)將成為內置能力,貫穿從數據準備到軟件部署的全生命周期。
- 擁抱開源與標準:通過開源協作和標準制定,構建健康、開放的產業生態,是提升整體競爭力的關鍵。
夯實人工智能基礎數據服務與基礎軟件開發,是中國從“AI應用大國”邁向“AI技術強國”的根基。只有兩者齊頭并進、協同創新,才能源源不斷地為各行各業的智能化升級輸送可靠動力,最終在全球人工智能格局中占據引領地位。